
Categories: Medium – ML:70% CTF:30% #data #visual
I was once looking through social network videos, and in one of them I noticed the password for the account
[email protected]. The person recording the video had accidentally revealed it!Alas, the password turned out to be invalid, but it gave me a nice idea for an AI CTF task.
✱ ✱ ✱
You have 1000 random videos shared on social network. In one of these videos I have actually submitted the flag for this task!
The flag looks like
FLAG_...(noaictf{...}this time)
The “visual” tag was a bit of a hint for me because if it’s AI CTF, the “visual” tag tells us that we should use Vision-Language Models. But, there’s always a solution without AI. Let’s look at this challange.
1. Initial Examination
This AI CTF challenge revolves around identifying a hidden flag of the form FLAG_... inside one of 1000 YouTube videos. The flag may appear in the video content itself — perhaps as text written on a screen, a piece of paper, or subtly embedded in the visual scene — and not necessarily in the description, subtitles, or metadata.
This makes it a perfect use case for modern Vision-Language Models (VLMs) like OpenAI’s GPT-4V, Google Gemini, Anthropic Claude with vision, or Meta’s ImageBind. These models are capable of understanding both visual content and language jointly, allowing them to “look” at images and “read” or “reason” about what they see.
So, I have three ways to solve that question.
2. Approaches to Solving the Challenge
2.1. Traditional Approach (Baseline)
Simply, the idea that to the solution of the problem was – in my opinion – the possibility of the YouTube video being released soon. The reason I thought that looked at the release dates of a few videos and thought they were pretty old and irrelevant. I thought this video belonged to the CTF team and I would see a phrase like “FLAG_…” somewhere in the video. So it could be a video close to the CTF date. That’s why I prepared a python script.
This Python script efficiently extracts YouTube video information and saves it to a CSV file.
How It Works:
- It fetches the content of a given web page to find YouTube video links.
- For each discovered YouTube link, it uses
yt-dlpto pull metadata like the video’s title and publish date. - To handle YouTube’s rate-limiting, the script incorporates an increasing delay and retry mechanism for each video request, ensuring more reliable data retrieval.
- Finally, it sorts all collected video data (URL, title, and publish date) from newest to oldest and exports it into a CSV file.
Why Specific Libraries Are Used:
requests: For making HTTP requests to download the HTML content of the target web page.BeautifulSoup(bs4): For parsing the HTML content, allowing easy navigation and extraction of video links.re: For using regular expressions to accurately identify and extract YouTube video IDs from various URL formats.yt_dlp: This is the core library for fetching detailed metadata (like title and publish date) for each YouTube video. It’s chosen over the official YouTube Data API to avoid the need for API keys and Google Cloud setup.time: Used to implement delays between requests, crucial for avoiding YouTube’s rate limits.datetime: For handling and formatting the publish dates, enabling proper sorting.csv: For conveniently writing the structured video data into a standard CSV file format.
After the python script runs, it outputs the publication dates, sorted from newest to oldest, as a .csv file.
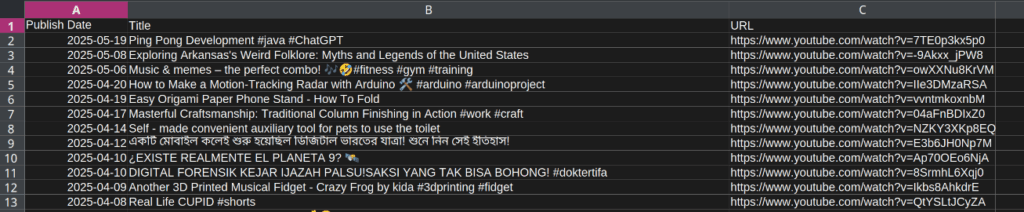
As you can see, the date of the video in the first place seems very close to the ctf date. Let’s look at this video.
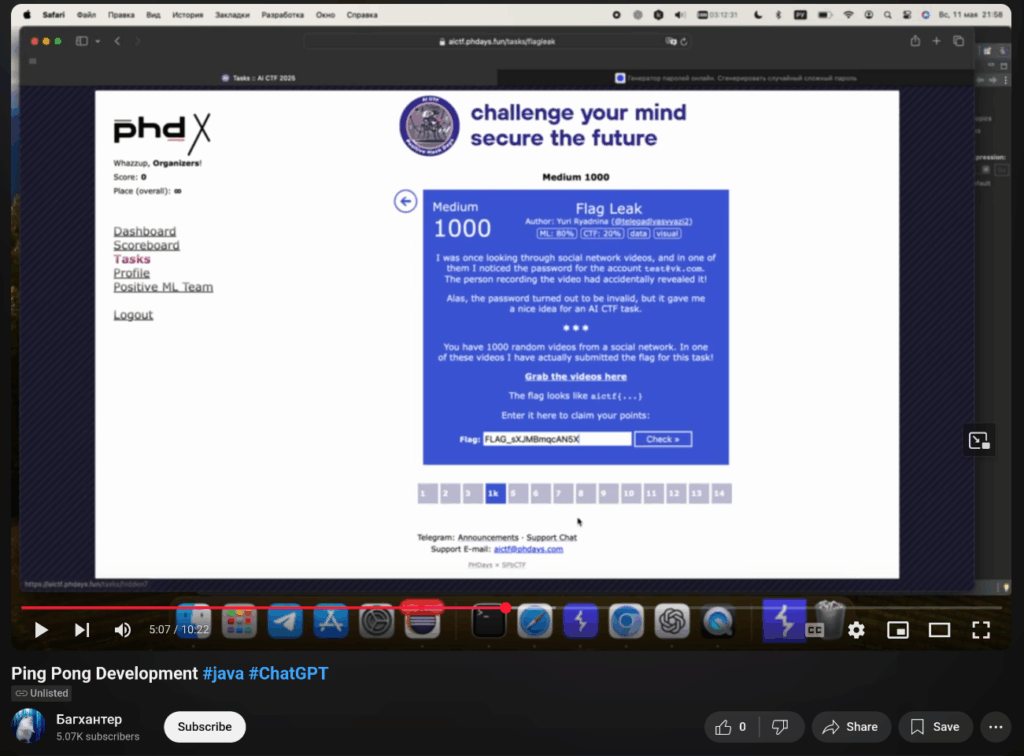
This video appears to be an unlisted video from user named “Багхантер” (Bughunter 😉 ). The video definitely needed to be watched carefully. To be honest, I was sure it was this video, but I think there was nothing about the flag for 5 minutes. Of course, there was no sound in the video. And, I can say that it was very boring to watch a video without sound for 5 minutes and look for signs of the flag. (хахаха)
At the end of patience Flag: FLAG_sXJMBmqcAN5X
Maybe think it was luck, but if all signs point in the right direction, it won’t be a waste of time to persist. But I already have second plan.
2.2. Text Extraction with Tesseract OCR
In this step, we used Tesseract OCR to detect text that appears within frames extracted from YouTube videos.
The script performed the following operations:
- It read YouTube video URLs from
deneme.txt. - Videos were downloaded and a frame was extracted every second.
- Each frame was:
- Converted to grayscale
- Enhanced with adaptive thresholding
- Resized to make small text more legible
- Tesseract OCR was used to extract text from the frame
- The extracted text was normalized (e.g.,
F L A G _→FLAG_) - If any text starting with
FLAG_was found, the script printed it and exited
This solution is a classical OCR approach based on pixel-level pattern recognition. Its performance is limited in cases with stylized fonts or poor contrast.
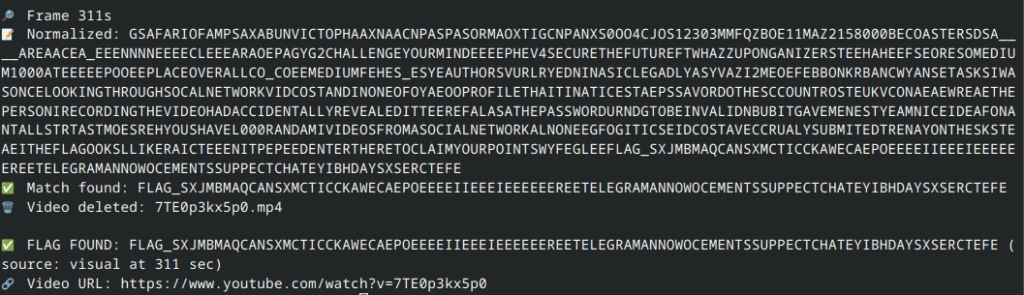
Of course, The flag needed some editing, but since script already did everything we needed, we can just move on to the video and check the flag.
2.3. VLM-Based Solution
In this solution, we used a Vision-Language Model (VLM) to detect FLAG_... patterns in frames extracted from YouTube videos.
Unlike traditional OCR (like Tesseract), a VLM can understand and interpret text within an image using semantic context.
The script followed these steps:
- Read YouTube video URLs from
video_urls.txt. - Downloaded each video using
yt_dlp. - Extracted one frame per second from each video.
- Sent each frame to a LLaVA 1.5 vision-language model.
- Provided the model with the following prompt: “This is a frame from a CTF video. If you see any text starting with
FLAG_, extract and return it exactly. Otherwise, say ‘No flag found’.” - If a
FLAG_...string was detected in any frame, the model returned it and the script stopped.
This script can successfully extract flags even from visually noisy, distorted, or stylized text that traditional OCR would fail to recognize.